本文是基于2026年面向对象课程第一单元迭代作业的总结
目录:
程序结构
以下数据分析自最终一次迭代的代码,全项目共计 20 个核心业务类,业务代码总计约 1080 行,包含 126 个方法。
hw3完整类图: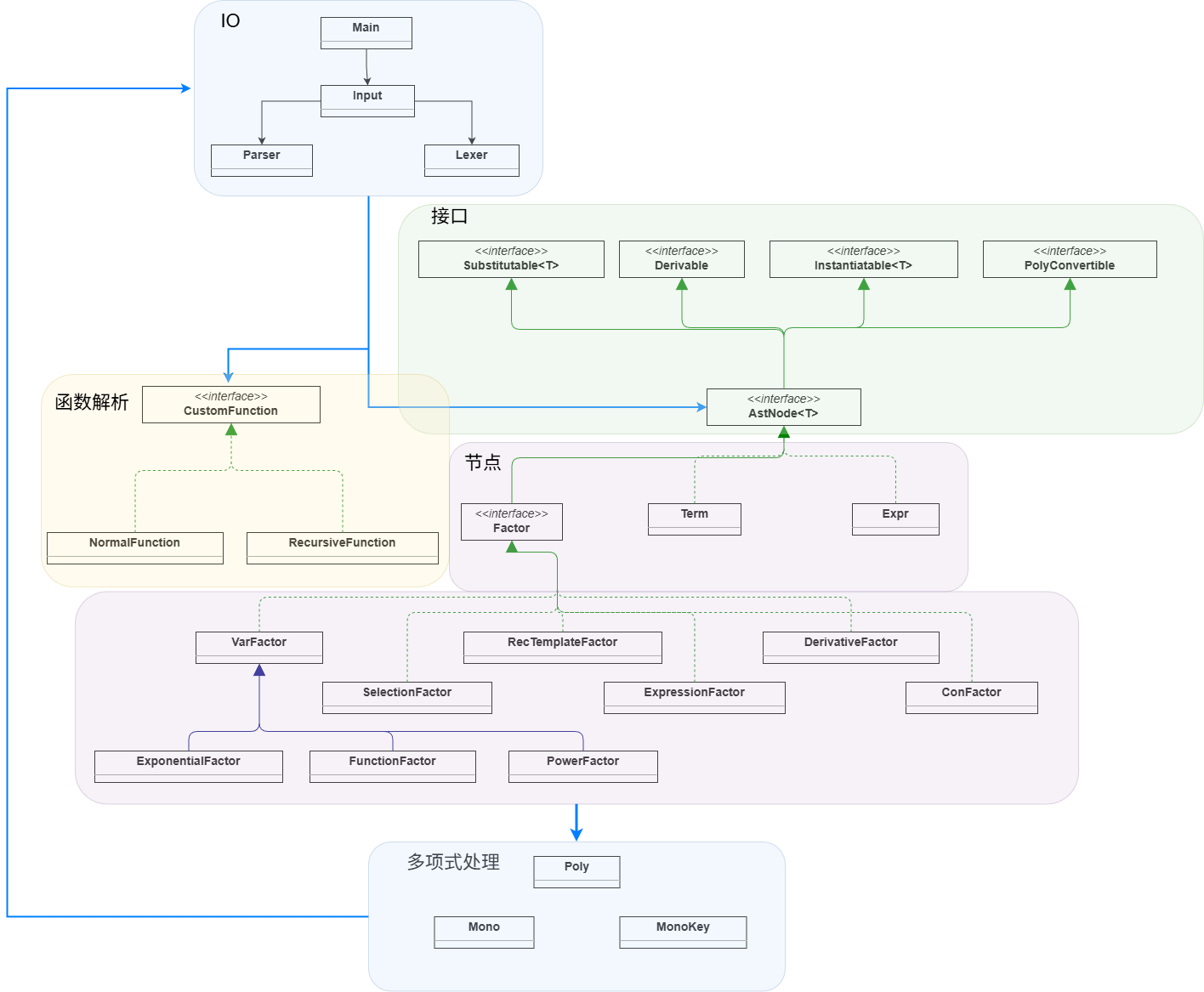
基础程序结构度量分析
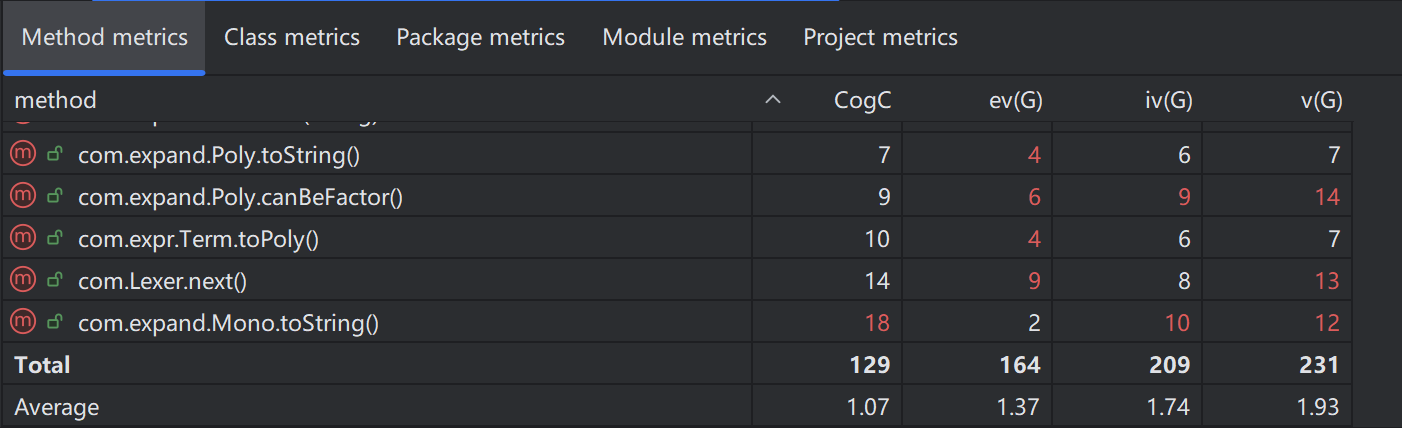
类总代码规模 (Class LOC)
- 代码规模最大的两个类分别是全局语法树构建工厂
Parser(184 行)与底层代数运算Poly(180 行),两者自然承担了系统中最密集的逻辑调度与计算任务。 - 绝大多数 AST 节点类(如
ConFactor,FunctionFactor)的代码量均被严格控制在 20-40 行之间。它们居于解析与运算之间,仅作为纯粹的数据结构存在,代码轻量。
- 代码规模最大的两个类分别是全局语法树构建工厂
方法个数 (NOM) 与 属性个数 (NOF)
Poly类的方法数最多(17 个),其次为Parser(12 个)。- AST 节点通常只有 1-2 个基础属性
方法规模 (Method LOC)
- 全项目 126 个方法,平均代码行数仅为 8.16 行
- 最长的方法
Mono.toString()为 47 行,而求导核心逻辑(各类节点的derive方法)普遍在 2-5 行。
控制分支数目 (圈复杂度 v(G))
- 全项目方法的平均圈复杂度(v(G))仅为 1.93
- 极低的圈复杂度是多态(动态分派)机制带来的直接收益。本架构彻底消除了传统面向过程编程中冗长的
if-else / switch类型判断,将共性操作下放至各自的子类中,实现了真正的 O(1) 逻辑寻址。
经典 OO 度量(内聚与耦合分析)
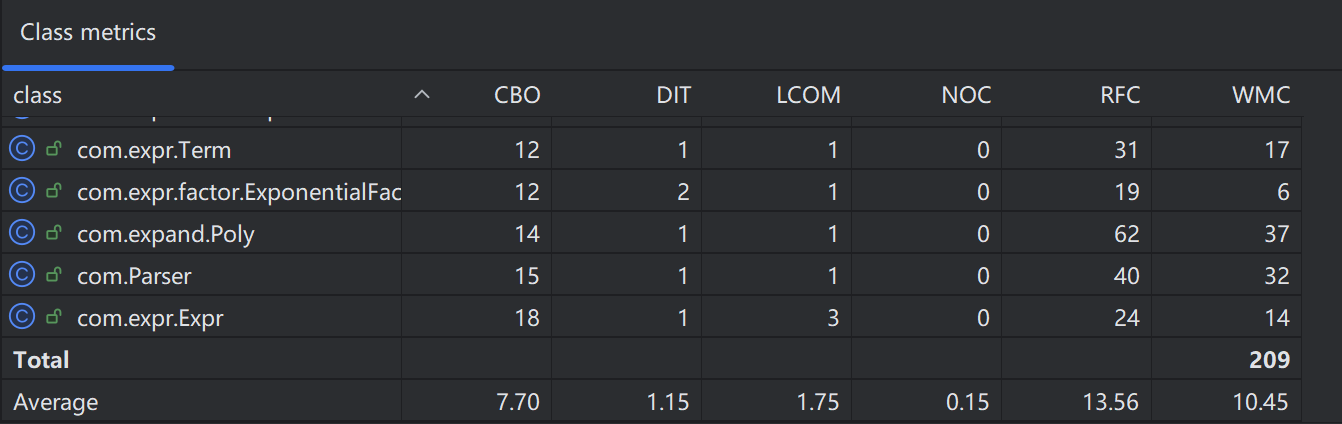
类的相互耦合情况 (CBO - Coupling Between Object classes)
- 系统耦合度最高的前三个类依次为
Expr(CBO=18)、Parser(CBO=15) 和Poly(CBO=14)。 - 而底层的原子节点(如
PowerFactor,ConFactor)的 CBO 极低(通常在 2-4 之间)。
- 系统耦合度最高的前三个类依次为
类的内聚情况 (LCOM - Lack of Cohesion of Methods)
- 全项目,LCOM 的最高值仅为 4,绝大部分类维持在 0 到 3 之间。
Poly类 LCOM 也低至 1.0,是一个内部方法高度共享核心状态、职责极其聚焦的高内聚模块。
基于类图的分析
整体思路:Input->Parser->toPoly->toString
Input:处理输入与预处理Parser:将字符串解析为各个类的实例toPoly:将AST上的节点统一转为Poly,方便合并、化简和输出。toString:针对mono和poly类进行统一递归输出。
优点:
- Dumb AST, Smart Engine 的分层架构**:
AST 树在解析和求导阶段保持绝对的纯粹,所有的计算全部推迟并集中在底层的Poly中。这种单向依赖保证了极低的类间耦合。 - 多态的实现:
通过动态分派机制,彻底消除了面向过程编程中常见的、冗长的switch/if-else类型判断。求导逻辑被完美下放至各自的 Factor 子类中,代码的扩展性与可读性极佳。 - 不可变性与线程安全隐患的规避:
在底层的多项式运算(如mulP)和替换操作(substitute)中,系统大量采用深度拷贝和构建新对象的方式返回结果,杜绝了引用传递可能导致的脏数据污染,保证了高阶求导与复杂嵌套替换时的绝对稳健。
- Dumb AST, Smart Engine 的分层架构**:
缺点:
- HashMap 带来的内存冗余开销:
为了追求 $O(1)$ 的同类项合并速度,底层大量实例化了MonoKey和Mono对象。在应对极其极端的嵌套乘方测试样例(如expP(8)的超高次展开)时,会产生大量的短生命周期对象,对 JVM 的垃圾回收(GC)造成了较大的内存压力。未来可考虑引入享元模式(Flyweight Pattern) 对某些单项式特征进行缓存。 - 解释器模式 (Interpreter) 的扩展性局限:
当前架构将derive和toPoly方法直接硬编码在了每个 AST 节点类中。如果未来需求增加(例如要求支持积分操作等),则需要打开每一个类的源码进行修改,这在一定程度上违背了“开闭原则(OCP)”。
在后续的重构中,可以引入访问者模式(Visitor Pattern)。将 AST 彻底退化为纯数据结构,将“求导”、“化简”等操作抽象为独立的 Visitor 类,实现数据与算法的彻底解耦。
- HashMap 带来的内存冗余开销:
架构设计体验
本次作业经历了三次迭代,在此过程中架构
迭代过程
- hw1
程序入口如下:
1 | public class Main { |
可见一开始就确立了基于**递归下降算法(Recursive Descent)**的 Lexer-Parser整体思路,构建了 Expr -> Term -> Factor 的基础抽象语法树(AST)
此时也只需处理简单的多项式合并于化简
hw2
随着括号嵌套(表达式因子)和指数函数(exp)的引入,单纯的 AST 遍历无法应对极其复杂的代数展开。
为了处理最终式子的合并于输出,最终剥离了 AST 的计算职责,专门抽象出了底层代数引擎——Poly(多项式)与Mono(单项式)。通过构建HashMap<MonoKey, BigInteger>,将复杂的代数合并转化为了 $O(1)$ 的哈希表聚合。
同时实现了架构解耦:将表达式的解析、展开(函数替换、选择式求值)、合并和输出(化简、格式化)设计为相对独立的模块,有助于降低系统的复杂度,使代码更易于维护和调试。hw3
本次作业加入自定义递归函数调用和嵌套求导算子(dx),在获取输入阶段就将函数定义的字符串也解析为一棵AST数,在调用函数时直接进行树节点的代换即可,提高了效率。
对于递推函数的展开,我采用记忆化搜索的思想来处理递推函数的展开。将已经计算过的 f{i}(实参) 的结果缓存起来,可以有效避免重复计算,提升程序性能。
自定新迭代情景与可扩展性分析
假如下一次需要引入三角函数(sin, cos)并支持其内部的复杂表达式嵌套与链式求导。
则当前设计的可扩展性应对方案:
- AST 层扩展:
- 新增
SinFactor和CosFactor类,实现Factor接口。 - 内部持有一个
Factor inner属性(用于存放嵌套的表达式)。
- 新增
- 多态求导逻辑:
在SinFactor内部实现derive()方法:直接return new Term(CosFactor(inner), inner.derive()),完美契合现有的链式求导法则。原有Expr和Term的遍历求导逻辑不必修改。 - 解析层处理:
在Parser.parseFactor()的多路分支中,新增对 “sin” 和 “cos” 字符串的识别,并实例化对应的 Factor 即可。 - 底层引擎(无需重构):
- 若三角函数无需展开化简,直接将其包装在
Poly的MonoKey中作为不可变特征处理即可。现有的加法、乘法合并引擎同样。
- 若三角函数无需展开化简,直接将其包装在
得益于 AST 节点的高度自治与多态分派机制,本架构面对“新增数学规则”的迭代时,表现出了极强的横向扩展能力。
使用到的设计模式 Design Patterns
组合模式(Composite Pattern)
整个 AST 结构中,无论是独立的个体对象(例如变量 $x$ 或常数 $5$),还是包含复杂子对象的容器(例如表达式 $x + 5$),都需要以完全一致的方式进行处理。
通过使用Factor接口,当Term对象对其持有的Factor列表调用derive()方法时,无需关心该Factor究竟是一个简单的变量,还是一个层层嵌套的复杂函数。它只需信任并依赖于该接口即可。静态工厂方法(Static Factory Method)
在Expr类中编写的public static Expr zero()和public static Expr of(Factor... factors)这两个方法,它们为对象的创建过程提供了清晰且富有语义的命名。在未来的开发中,如果你决定让Expr.zero()方法不再每次都通过new Expr()来创建新对象,而是改为返回一个经过缓存的、不可变的单例对象,完全可以轻松实现这一变更,而无需修改任何调用了该方法的现有代码。单例模式(Singleton Pattern)
因为全局只有一个函数模板,所以为其实现单例模式:
1 | public class FuncDefinition { |
可以改进增添(以下由AI建议给出):
Visitor 访问者模式
目前架构采用了解释器模式。每一个节点都知晓如何对自己进行求值或求导(例如,PowerFactor 类拥有其专属的 derive() 和 toPoly() 方法)。
这种设计存在一个致命的缺陷:如果你想要新增一种操作,该怎么办? 假设想添加一个 printToXML() 方法、calculateIntegral() 方法,或者 formatToLaTeX() 方法。就不得不逐一打开 Expr、Term、ConstantFactor、VarFactor 等类文件,并把该方法添加到每一个类中去。在这种模式下,数学运算逻辑不再内嵌于各个节点之中;相反,节点只需负责“接纳”一位“访问者”即可:
1 | // The Node just says "Welcome, Visitor! Here I am." |
分析自己程序的bug
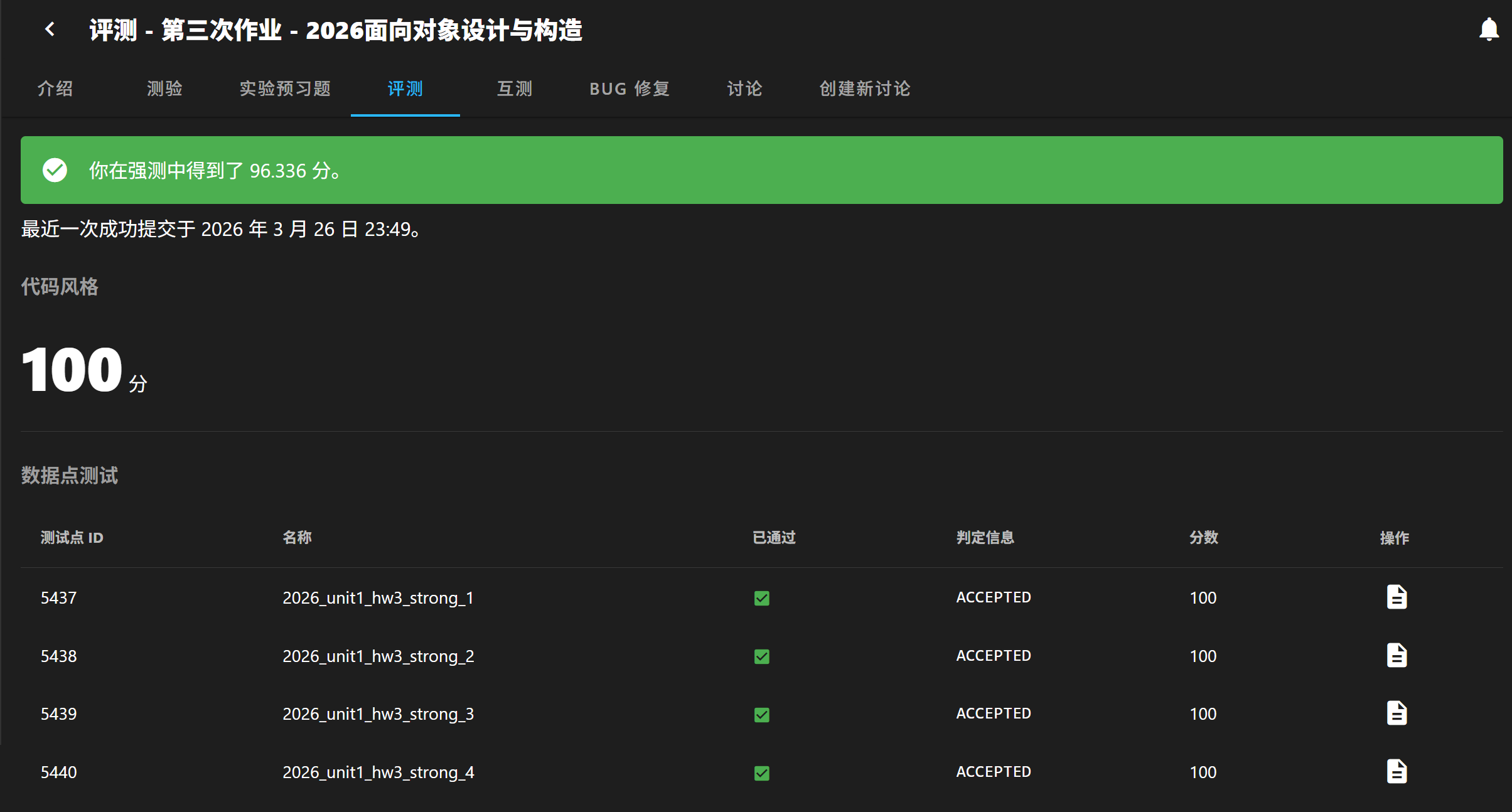
这部分没什么可写的,因为三次作业的强测和互测中均实现了 0 bug,这也得益于rwg老师强调的这个理念:
不要为了性能牺牲正确性
在第二三次迭代中我均首先保证了多项式合并的正确性,而没有着重处理exp式子中系数提取与化简的处理,因而可能优化分不高,但确实这也是我能保证程序没有bug的方法。
同时为了避免bug,在程序中我也为不希望改变的量赋予final属性,元素赋值时实现深克隆,格外注意对容器元素的删除时可能产生的问题,以免产生意料之外的问题。
长代码行和高圈复杂度也是产生bug的诱因,通过降低这些方法的复杂度,可以显著降低产生bug的几率。
其实关于hw3还有一点想吐槽:这次作业我没怎么做最终长度优化导致互测进入了b房(正确性满分但性能分不高),而b房的大家都是同样的情况,导致hack也没什么结果,相比之下a房因为优化的问题可以hack出很多点。这样就导致a房既有了高强侧分,又有了高hack分,这不是鼓励大家为了性能舍弃正确性吗?
分析自己发现别人程序bug所采用的策略
- 主要:构造评测机,高效,可以发现少量bug,效果取决于评测机的质量。
- 构造极端样例:有效,但样例构造有难度。
- 阅读对方代码(白盒测试),针对其设计缺陷构造用例。
分析自己进行的优化
基于哈希与正则化(Canonicalization)的 $O(1)$ 同类项合并
在多项式乘法和高阶展开(如(x+1)^8)中,如果采用传统的双层List遍历对比同类项,时间复杂度将达到灾难性的 $O(N^2)$。
通过提取单项式的不可变数学特征(x 的指数、y 的指数、嵌套表达式内容)封装为MonoKey类,并重写equals和hashCode。
实现了通过HashMap<MonoKey, BigInteger>的快速系数合并。基于多态的快速求导与多项式转换
为所有类继承自interface AstNode<T>,实现逻辑的统一。
1 | public interface AstNode<T> extends |
- 本架构的正确性由绝对的不可变性(Immutability) 和**深拷贝(Deep Copy)**来保证。在进行
Poly.mulP(多项式相乘)或expP(乘方)等操作时,每次计算都会new出全新的Poly和Mono对象返回。虽然牺牲了一定的内存,但彻底杜绝了引用传递导致的各种隐患。
大模型相关使用
代码生成使用率
- AI 生成代码占比:0%
- ——作业中所有的的代码均由我自己编写。虽然AI的能力很强,但总归自己去写下每一行代码,才能真正掌握编写的能力。
大模型的实际应用场景与心得体会
虽然不会让大模型直接生成代码,但其实llm深度参与了我的代码编写过程:
不像当初学c语言的时候,会从每一个语法、每一个细节讲起,OO课程上我们直接面对的就是一千多字的题目要求和几百行待编写的代码,这意味着一切java的语法或实现任务的细节都需要我们自学。
自学有很多种方法:看jkd文档、看网上如菜鸟教程、看网课,或是直接问AI。可以想象,之前的人们学习java时,会在各种文档doc与教程中寻觅(去年我学习c语言也是这样的),而这样的搜索往往费时而可能缺乏深度,而如今的AI可以基本替代掉上述过程。
比如我想学习什么是单例模式,直接问AI即可,它会给出不同单例模式的实现方式,进一步的,你还可以问它具体到我的任务上选择哪种最好,或是单例模式的原理是什么。
对比这种模式,与从网上某个网页中复制粘贴一段自己也不怎么能看懂的代码并然后修修改改,前者的优点显而易见:具体的、有针对性的、而深入的。
除去这种可能网上也能找到的理论方面的指导,AI最关键的帮助还是帮助提供工程化的思路和自己认知之外的代码逻辑优化。现在,不用自己读完一本《The Art of Computer Programming》,直接把自己的思路发给AI,跟它说:“假设你是一名高级java工程师,对这段代码有什么建议?”我就可以收到有效的改进意见,提升自己的能力与认知。
大模型评价
大模型回答的质量取决于人提供的Prompt。为了达到让AI辅助自己学习的目的,显然不能让它直接把代码生成出来(而且很多时候它生成的代码有许多问题),而是要让它或是引导自己,或是提供建议。
所以我在对话开始使用了这样的prompt:
你现在是一位资深java工程师,来指导我完成代码,始终记得,你在我没有要求的情况下不得给出代码答案。你只是协助我完成任务,回答我的问题,顺着我的思路来思考分析,绝不能在我之前将答案告知我
遇到潜在的bug也不要提醒我,留给我让我自己发现。
不要提供任何我询问内容以外的信息
效果在最开始还不错,但随着上下文的增多,llm有说也会直接把代码全写出来。
总之,使用AI确实让我提高了java水平、培养了面向对象的思想,也更深入地了解了一些底层的原理(通过随时向llm发问)。我也相信,使用AI技术所学到知识将多于不使用AI时的学习,而重点在于使用方式的正确性。
未来方向
你觉得可以如何修改第一单元的课程,让大家更好的进行第一单元的学习:
可以针对作业中所用到的设计模式、或某些语法给出更多的教程或提示,第一次迭代时的公众号文章就对我的设计有很多帮助,希望每次作业都有类似的引导。
思考题
如何检查输入是否符合要求?包括空格,连续符号等。
拦截非法组合
评测机的 Lexer 必须对空白符非常敏感。- 数字内空格切断:当读入数字时,如果紧跟空格,Lexer 必须将后续的数字识别为新的 Token。例如
12 34会被解析为[NUM(12), NUM(34)]。 - 连续符号聚合:对于
+++或---,Lexer 可以将其作为连续的单字符 Token 输出,交由语法层判断 - 非法字符白名单:遇到任何不在
[0-9x\+\-\*\(\)\s\^sincosp]集合内的字符(如全角空格、制表符的变体),立即在词法阶段拦截。 - 长度断言:删除所有空白字符后,检查字符串长度是否超出要求限制。
- 数字内空格切断:当读入数字时,如果紧跟空格,Lexer 必须将后续的数字识别为新的 Token。例如
形式化语法层(Parser):拦截非法结构
- 递归下降断言:利用递归下降算法构建一棵“虚拟的验证树”。如果刚才的
12 34传到 Parser,Parser 在期望读到操作符(Operator)的地方读到了第二个NUM,直接抛出 SyntaxError(WF)。
- 递归下降断言:利用递归下降算法构建一棵“虚拟的验证树”。如果刚才的
如何精确计算一个合法输入的 cost?
- 原样建树。使用 Parser 将输入字符串解析为 AST,不进行任何数学化简
- 自底向上算cost。
本文同步发布于:https://blog.csdn.net/Gooden_job/article/details/159551046